
Started with looking up our area on antennaweb: entered my address and it gave me directions and this map.
The site also say that frequency ranges have colors, and that I have to choose an antenna that has the right colors.

Since there's over 60 miles from my home to San Francisco, the only reasonable choice was ChannelMaster 4228D - they sell it at Fry's.
Turned out that to install it I need more than just this box. I need a pole and the stuff to attach the pole to the roof. Below I explain what I did. I bought a 5-foot piece of "black pipe" at Lowe's (here on the picture the end of the pipe), a cap for the pipe and the piece which I want to attach to the roof. |   | ||
You need a cap on top so that rain won't penetrate the pipe. Before attaching the bottom piece to the roof, I had patched the area below with roof coating, to avoid leaks: |   | ||
Now we need these things from OSH (electric department and bolts and nuts department) to attach to the pole the guy wire that will hold it. |  | ||
This is how the top of the pole looks like with all the stuff attached: |  | ||
I have attached two eye screws to the sides of my roof, and two went straight into the roof: |
| ||
After I drilled the hole for the screw, I patched it so the rain won't get in: |   | ||
Now I have to attach the guy wire to the pole and to the eye screws; for this I use clams: |
| ||
The guy wire does not go all the way through from the top of the pole to the screws. I cut the wire and attached turnbuckles that allow me to tighten the wires later: |   | ||
This is how it looks with antenna attached to the pole using brackets, and the guy wires tightened with turnbuckles. |  | ||
Now it's time to get the cable into the house. I bought a 25-foot white coaxial cable, connected it to the antenna's amplifier, got it along the roof and the wall. |  | ||
I had measured the position of an existing tv socket inside the room, and used a long drill to drill through the wall to get to the socket as close as possible. |  | ||
I used this bushing for the cable to get through. Bought it at Lowe's. |  | ||
Had to cut the bushing, or else how would I get the cable through? |  | ||
When I got the cable through the wall, I applied a good amount of clear caulk to make sure no water gets through. |   | ||
I was lucky, the cable got exactly where I wanted it. |  |




So all I had to do is connect my tv, scan the 56 channel it found and enjoy the show.
And you know what? It sucks. I don't have a dvr on those channels, so there's no way I can pause it, or get any information regarding what is it about... no recording. And the channels... what nonsense people watch, omg.
So, was it all worth it? Probably. I had fun with my antenna.
Here's a photo I took from a digital channel:


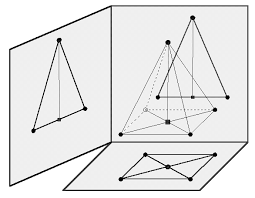 the pyramid here is neither a square nor a triangle. But when projected, it can be percieved as one. If we say "he's a soldier", it does not mean that's all the person is; what we mean is just a projection.
the pyramid here is neither a square nor a triangle. But when projected, it can be percieved as one. If we say "he's a soldier", it does not mean that's all the person is; what we mean is just a projection.{kind=link}